机器之心编辑部
近年来,人工智能模型的能力显著提高。其中,计算资源的增长占了人工智能性能提升的很大一部分。规模化带来的持续且可预测的提升促使人工智能实验室积极扩大训练规模,训练计算以每年约 4 倍的速度增长。
从这个角度来看,人工智能训练计算的增长速度甚至超过了近代史上一些最快的技术扩张。它超过了移动电话采用率(1980-1987 年,每年 2 倍)、太阳能装机容量(2001-2010 年,每年 1.5 倍)和人类基因组测序(2008-2015 年,每年 3.3 倍)的峰值增长率。
在最近的一份报告中,Epoch AI 研究了当前人工智能训练规模的快速增长(约每年 4 倍)在 2030 年之前是否始终在技术上可行。
报告提到了可能制约扩展的四个关键因素:电源可用性、芯片制造能力、数据稀缺性和「延迟墙」(人工智能训练计算中不可避免的延迟所造成的基本速度限制)。
报告中的分析包括生产能力的扩张、投资和技术进步。除其他因素外,这包括审查先进芯片封装设施的计划增长、额外发电厂的建设以及数据中心利用多个电力网络的地理分布。为了考虑这些变化,报告纳入了各种公开来源的预测:半导体代工厂的扩张计划、电力供应商的产能增长预测、其他相关行业数据以及自己的一些研究。
他们发现,到本个十年末,2e29 FLOP 的训练运行或许是可行的。换句话说,到 2030 年,我们将很有可能训练出规模超过 GPT-4 的模型,与 GPT-4 在规模上超过 GPT-2 的程度相同。如果继续努力,到本个十年末,我们可能会看到人工智能的巨大进步,就像 2019 年 GPT-2 的简陋文本生成与 2023 年 GPT-4 的复杂问题解决能力之间的差异一样。
当然,人工智能开发者是否真的会追求这种水平的扩展,取决于他们是否愿意在未来几年投资数千亿美元用于人工智能的扩展。但这不是报告讨论的重点。
在整个分析过程中,报告假定训练运行可持续 2 到 9 个月,这反映了持续时间越来越长的趋势。报告还假设,在为分布式训练和芯片分配人工智能数据中心电力时,公司只能获得现有供应量的 10% 到 40% 左右。
制约扩展的四个关键因素
电力限制
人们已经讨论过,到 2030 年数据中心园区达到 1 至 5 GW 的计划,这将支持 1e28 至 3e29 FLOP 的训练运行(作为参考,GPT-4 可能在 2e25 FLOP 左右)。地域分布式训练可以利用多个地区的能源基础设施,进一步扩大规模。根据目前美国数据中心扩张的预测,美国的分布式网络可能容纳 2 到 45 GW,假设数据中心之间有足够的带宽,则可支持 2e28 到 2e30 FLOP 的训练运行。除此之外,如果提前 3 到 5 年进行规划,愿意支付新发电站成本的参与者可以获得更多电力。

数据中心电力容量的快速扩张潜力巨大,这一点已被多种资料来源和预测所证实。SemiAnalysis 提供的历史数据显示,2019 年至 2023 年期间,数据中心容量的年增长率约为 20%(如图 2)。2024 年和 2025 年的扩建计划旨在加快这一速度,如果按时完成,年增长率将达到 32%。
总体而言,10-30% 的年增长率似乎是可以实现的。根据 15% 的中心增长率估算,到 2030 年,美国数据中心的容量将从 40 GW 增长到 90 GW,即增加 50 GW。注意,此处使用的是对实际增长的预测范围,并以此为基础估算可行的增长,因此这一数字可以说是保守的。
报告中提到,由本地电力支持的 2030 年训练运行可能需要 1 到 5 GW,到 2030 年可达到 1e28 到 3e29 FLOP。与此同时,分布在各地的训练运行可获得 2 至 45 GW 的电力供应,并在数据中心对之间实现 4 至 20 Pbps 的连接,从而实现 2e28 至 2e30 FLOP 的训练运行。上述估计背后的假设可以在下图 3 中找到。

芯片制造能力
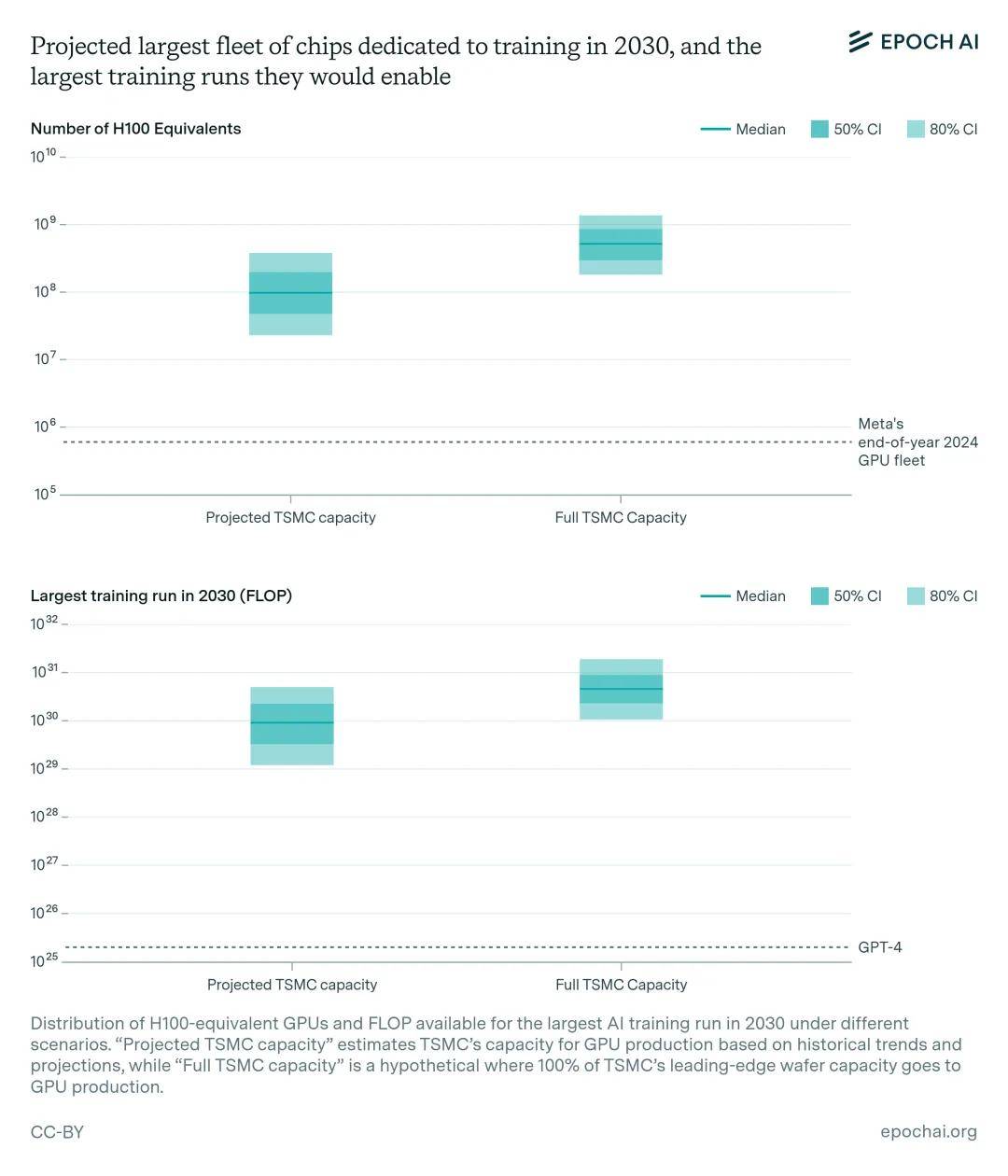
人工智能芯片提供了训练大型人工智能模型所需的计算能力。目前,扩展受到先进封装和高带宽内存生产能力的限制。不过,考虑到制造商计划的规模扩张以及硬件效率的提高,即使考虑到 GPU 将在多个 AI 实验室之间分配,并且部分专用于服务模型,也可能有足够的能力让 1 亿个 H100 等效 GPU 专用于训练,为 9e29 FLOP 的训练运行提供动力。然而,这一预测具有很大的不确定性,估计值从 2000 万到 4 亿个 H100 等效处理器不等,相当于 1e29 到 5e30 FLOP(比 GPT-4 大 5000 到 300000 倍)。
报告中假设了一种情况,即从现在到 2030 年,台积电 5 纳米及以下的全部产能都用于 GPU 生产。在这种情况下,潜在计算量可能会增加一个数量级,达到 1e30 到 2e31 FLOP。这一上限基于当前的晶圆产量预测,说明了如果完全解决封装、HBM 生产和晶圆分配方面的现有限制,对人工智能训练能力可能产生的最大影响。图 4 展示了这些估计值,并列出了其背后的假设。
数据短缺
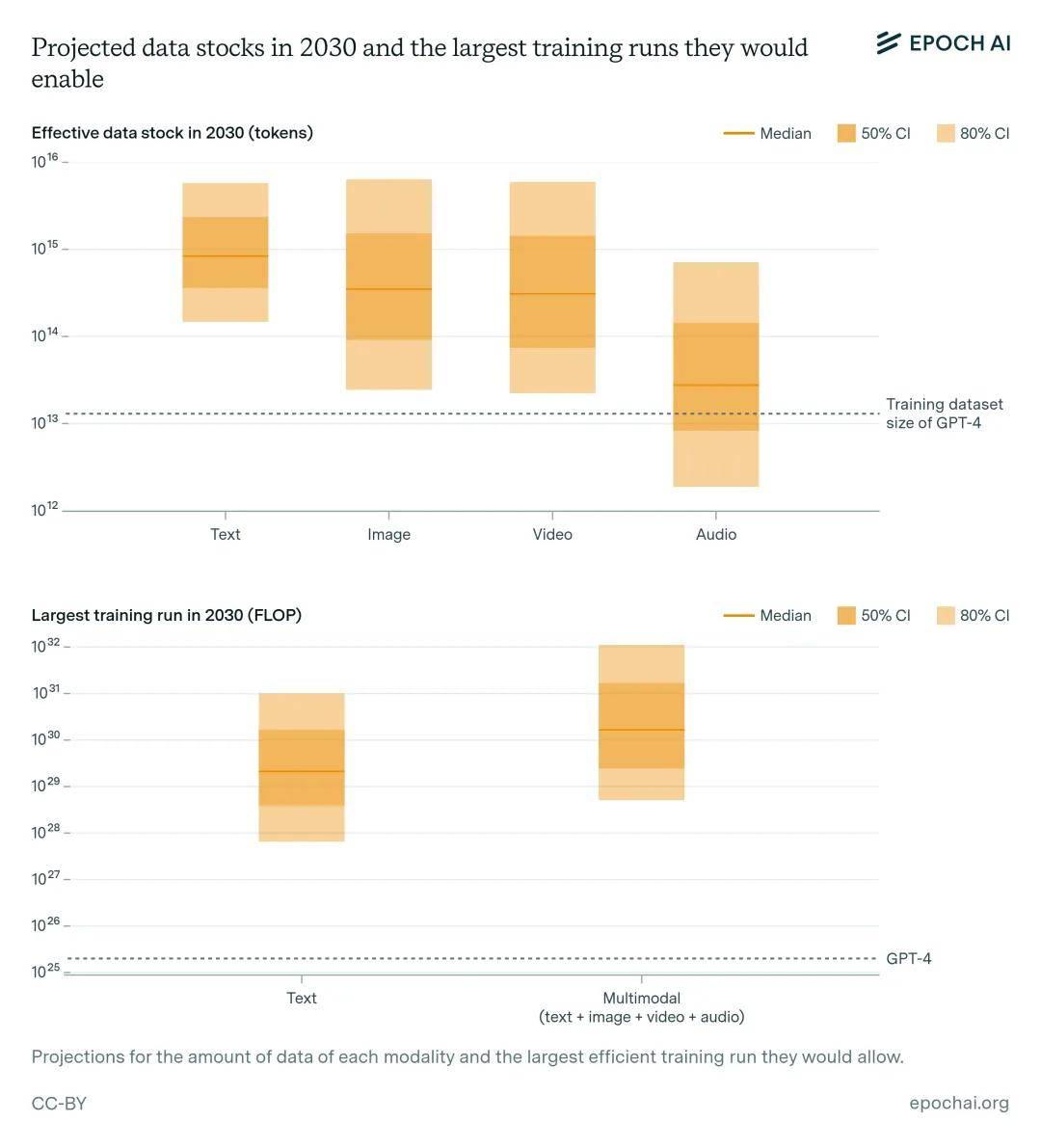
训练大型人工智能模型需要相应的大型数据集。索引网络包含约 500T 的独特文本,预计到 2030 年将增加 50%。从图像、视频和音频数据中进行多模态学习可能会适度促进扩展,使可用于训练的数据增加三倍。在考虑了数据质量、可用性、多 epoch 和多模态 tokenizer 效率等不确定因素后,估计到 2030 年可用于训练的 token 相当于 400 万亿到 20 亿亿个,允许 6e28 到 2e32 FLOP 的训练运行。人工智能模型生成的合成数据可能会大幅提高这一比例。
据估计,索引网络上的文本数据量为 20 亿亿个 token (Villalobos et al, 2024)。同时,互联网上图片和视频秒数的估计值为 40 万亿。如果也使用每张图片或每秒视频 100 个 token 的高端估计值,这意味着有四亿亿个视觉 token,或六亿亿个文本和视觉 token。如果还假设到 2030 年这些数据量翻一番,80% 的数据因质量过滤而被删除(FineWeb 丢弃了约 85% 的 token),模型在这些数据上训练 10 个 epoch,那么有效数据集的规模将达到约 20 亿亿个 token。有关这些参数的完整列表以及报告选择这些值范围的理由,如图 5 所示。
延迟墙
延迟墙是一种 「速度限制」,源于向前和向后传递所需的最短时间。随着模型规模的扩大,它们需要更多的顺序操作来训练。增加并行处理的训练 token 数量(即「批大小」)可以摊销这些延迟,但这种方法也有局限性。超过「临界批大小」后,批大小的进一步增加会导致训练效率的回报递减,训练更大的模型需要连续处理更多的批。这就为特定时间范围内的训练 FLOP 设定了上限。报告估计,现代 GPU 设置上的累积延迟将使训练运行的 FLOP 上限达到 3e30 到 1e32。要超越这一规模,需要采用其他网络拓扑结构、减少通信延迟,或者采用比目前更积极的批规模扩展。
OpenAI 之前的研究将临界批大小(在这个点之后,训练的收益会大幅递减)与梯度相对于训练数据的分散程度联系了起来。在此基础上,Erdil 和 Schneider-Joseph(即将发表)推测,批大小可能与可还原模型损失的倒数成比例,根据 Chinchilla 的说法,可还原模型损失的比例大致为模型参数数量的立方根。如果这种情况成立,它将把延迟墙推回一个数量级,参见下图。

什么限制因素影响最深?
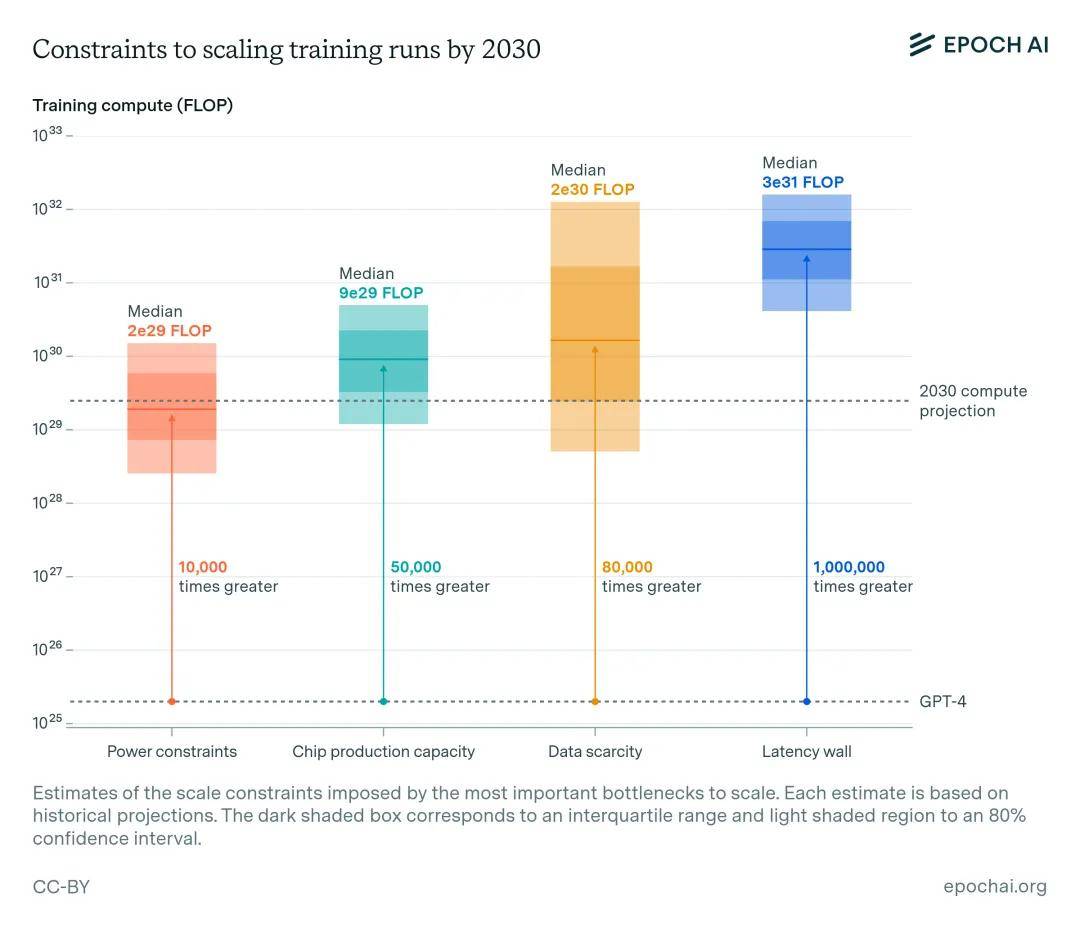
上文讲到了人工智能扩展的四个主要瓶颈。如果将它们放在一起考虑,则意味着到本个十年末,训练运行高达 2e29 FLOP 是可行的。这将代表着相对于当前模型的大约 10000 倍的扩展,并意味着扩展的历史趋势可以不间断地持续到 2030 年(图 7)。深色阴影框对应四分位数范围,浅色阴影区域对应 80% 置信区间。

最具约束力的限制因素是电力和芯片的可用性。其中,电力的可塑性可能更大,能源行业的集中度较低,而且有扩大 100 GW 电力供应的先例,如果提前三到五年计划,供应商应该能够执行。
扩大芯片制造面临多重挑战:先进封装等关键工艺大多已分配给数据中心的 GPU,而建设新的晶圆厂需要大量资本投资和高度专业化的劳动力。
数据是最不确定的瓶颈,其不确定性范围跨越四个数量级。多模态数据对提高推理能力的作用可能有限,而且我们对此类数据的可用存量、质量以及当前 token 化方法效率的估计都不如对文本数据的估计那么确定。最终,合成数据可以实现无限扩展,但计算成本较高。
最后,虽然延迟墙是一个遥远的制约因素,但它作为一个需要克服的障碍,已经出现在地平线上。通过采用更复杂的网络拓扑结构,包括更大的 pod 或 pod 之间更多的连接,可能会将延迟墙推倒。
AI实验室们会扩展到这个程度吗?
迄今为止,人工智能模型规模的不断扩大一直带来能力的提升。这为人工智能的发展灌输了一种以规模为中心的观点,导致用于训练运行的支出以每年约 2.5 倍的速度增长。早期迹象表明,这种情况可能会继续下去。
值得注意的是,据报道,微软和 OpenAI 正在为一个名为 Stargate(星际之门)的数据中心项目制定计划,该项目耗资可能高达 1000 亿美元,将于 2028 年启动。这表明,大型科技公司确实正在准备实现本文所述的巨大规模。
将 GPT-4 升级到与 GPT-6 相当的模型,再加上算法的大幅改进和后期训练的改进,可以进一步证明人工智能系统具有足够大的经济回报潜力。这些证据可能表现为:GPT-5 等较新的模型在发布的第一年内就创造了超过 200 亿美元的收入;人工智能功能的显著进步,使模型能够无缝集成到现有的工作流程中,操作浏览器窗口或虚拟机,并在后台 独立运行。
人工智能能够自动完成相当一部分经济任务,其潜在回报是巨大的。一个经济体投资数万亿美元建立与计算相关的资本储备,包括数据中心、半导体制造工厂和光刻机,是有可能实现的。要了解这一潜在投资的规模,需要考虑全球每年的劳动报酬约为 6000 万美元。即使不考虑人工智能自动化带来的经济加速增长,如果开发能够有效替代人类劳动力的人工智能变得可行,那么投资数万亿美元来获取这 6000 万美元中的一小部分,在经济上也是合理的。
据标准经济模型预测,如果人工智能自动化达到取代大部分或全部人类劳动力的程度,经济增长可能会加快十倍或更多。在短短几十年内,这种加速增长可使经济产出增加几个数量级。考虑到这一潜力,提前实现完全或接近完全自动化的价值可能占全球产出的很大一部分。认识到这一巨大价值,投资者可能会将传统行业的大部分资金转投人工智能开发及其重要基础设施(能源生产和分配、半导体制造工厂、数据中心)。这种前所未有的经济增长潜力可能会推动数万亿美元的人工智能开发投资 104。

