美东时间周二早间,互联网基础设施服务商Cloudflare表示,其全球网络正在遭遇异常,导致包括社交媒体平台X在内的大量网站出现“internal server error”等访问故障,用户无法访问许多网站和服务,包括零售、电商、社交媒体、金融服务以及交通相关平台。该公司随后声称,在耗时不到四小时后已修复问题。
宕机期间,X的部分功能中断,多家网站也陷入访问受阻。根据故障跟踪平台Downdetector的数据,除X之外,也有大量站点受到影响,相关报告数量持续攀升。用户在访问X、ChatGPT、DoorDash、IKEA,以及纽约市大都会运输署(MTA)等网站时,都看到与Cloudflare相关的错误信息。


随后,Cloudflare的一位女发言人表示,在美东时间早上6点20分左右,他们的某项服务出现了异常的流量激增,导致经过公司网络的流量出现错误。
Cloudflare另一位发言人Jackie Dutton在公告中说,这个问题是由一个用于管理威胁流量、自动生成的配置文件引起的,修复耗时不到四小时。公司表示已经部署了核心修复措施,但谨慎指出系统“仍需时间完全稳定”。
Dutton表示:
“这个文件的条目数量超过了预期大小,触发了负责处理Cloudflare部分服务流量的软件系统崩溃。”
声明称,没有证据显示此次事件与网络攻击或恶意活动有关。
故障的影响范围极为广泛。Downdetector在平台上表示,在Cloudflare宕机期间,“各类受影响服务的报告累计超过210万条”,显示此次事件已成为近年来较为严重的一次基础设施级别中断。
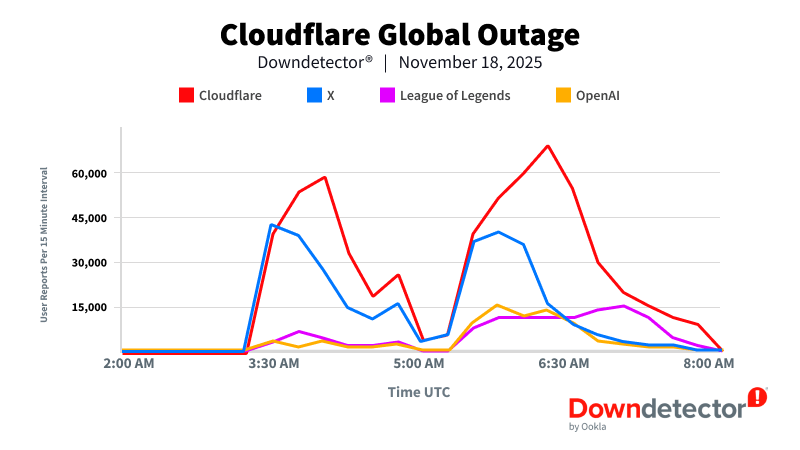
事故发生后,Cloudflare的股价周二开盘一度暴跌7%,随后跌幅收窄。
数字资产行业也出现反应。币安联合创始人、前CEO赵长鹏在X上发文称:“区块链依然正常运行(Blockchain kept working)”,暗示去中心化系统未受此次事件影响。
到美东时间12:15,Cloudflare表示系统正在逐步恢复,但全球部分区域仍可能出现访问错误、性能下降或登录问题。公司将在状态页面持续更新修复进度。

对少数公司过于依赖
近年来,多次因为数字基础设施供应商出现问题,导致全球互联网使用陷入瘫痪。亚马逊云服务(AWS)、CrowdStrike Holdings Inc.和微软公司先后出现过类似事故,也突显全球互联网在很大程度上依赖于少数公司提供服务。
Cloudflare和AWS的服务对普通用户来说几乎是“隐形”的,但它们的工具支撑着消费者每天使用的大量网站和服务。
上个月AWS的宕机让互联网部分区域陷入瘫痪,导致数百万用户的网站和应用无法使用,零售销售受阻,社交媒体和金融服务中断,很多企业也受到影响。去年,网络安全公司CrowdStrike所使用的一项工具中的漏洞更是让全球的电脑系统大面积崩溃,引发数千次航班延误和取消,也让政府机构和大型企业的运营陷入混乱。
加州网络安全公司Check Point Software的专家Graeme Stewart表示,这类事故凸显了互联网对少数几家基础设施提供商的过度依赖。
他说:
“很多机构依然让所有关键服务都依赖同一条路径,而且没有真正有效的备份。一旦这条路径出问题,就没有任何后备方案。这就是我们一直看到的问题。”
萨里大学(University of Surrey)网络安全教授Alan Woodward表示,周二的故障再次说明互联网高度依赖“少数玩家”。他把Cloudflare形容为“你从未听说过的最大公司”。
“人们别无选择,只能依赖这些少数大公司。”
首席技术官道歉
Cloudflare首席技术官Dane Knecht为这次事故道歉。他在X上写道:
“当Cloudflare网络出现问题,影响到依赖我们的海量流量时,我们辜负了客户,也辜负了整个互联网。这个问题本身、造成的影响、以及解决所花的时间,都是不可接受的。我们已经开始着手确保类似情况不会再次发生,但我知道今天确实给大家带来了麻烦。客户对我们的信任最为重要,我们会尽一切努力赢回这份信任。”
Cloudflare在过去几年曾多次经历类似宕机。
2019年7月,Cloudflare软件中的一个漏洞导致网络部分模块过度占用计算资源,使全球数千家依赖Cloudflare的网站(包括Discord、Shopify、SoundCloud以及Coinbase)离线长达30分钟。2022年6月,Cloudflare发生故障,影响其19个数据中心的流量,导致多个主要网站和服务瘫痪,持续约一个半小时。
Cloudflare的软件被全球数十万家公司使用,作为企业网站与终端用户之间的缓冲层,用于保护网站免受流量攻击或流量突发导致的宕机。
去年,网络安全公司CrowdStrike发布的错误软件更新导致运行微软Windows系统的数百万台设备崩溃,给航空、银行、医疗等众多行业造成大范围混乱。
CrowdStrike的这次宕机源于其产品中一个在客户电脑最底层运行的错误。而Cloudflare的作用是保护互联网基础设施,如网站和平台,因此当Cloudflare宕机时,许多热门网站会直接无法访问或出现异常。Cloudflare主要负责“让网站始终在线且速度够快”,而CrowdStrike专注于保护电脑和服务器免受攻击。

